By Brian Fitzgerald
Introduction
AutoUpgrade is a convenient utility for completing multiple database upgrades in parallel. AutoUpgrade was released undocumented in Oracle 18c, and was documented for the first time in the 19c manual:
The AutoUpgrade utility identifies issues before upgrades, deploys upgrades, performs postupgrade actions, and starts the upgraded Oracle Database.
Use AutoUpgrade to upgrade Oracle Database from version 11.2.0.4 and up. To use AutoUpgrade, prepare a simple configuration file and run autoupgrade.jar. Behind the scenes, AutoUpgrade runs all steps necessary to complete the upgrade. AutoUpgrade runs on a single host. If you want to migrate to a separate, new host, run AutoUpgrade preparatory steps on the Source (original) host. Then, copy the database to the new host and run the Upgrade step on the target host.
News about AutoUpgrade
Mike Dietrich is Oracle’s product manager for AutoUpgrade. Refer to his blog for news about AutoUpgrade. Future topics or changes could include coverage of new Oracle versions, RAC, Restart, Data Guard, and migrating directly from non-CDB to CDB.
Demonstration platform description
AutoUpgrade is demonstrated in this blog article. The system attributes of the demonstration system are:
| Attribute |
Value |
| location |
US East (N. Virginia) |
| instanceType |
c5.xlarge |
| tenancy |
shared |
| instanceFamily |
Compute optimized |
| physicalProcessor |
Intel Xeon Platinum 8124M |
| clockSpeed |
3.0 Ghz |
| Number of CPUs |
4 |
| memGB |
8 GiB |
| operatingSystem |
Linux |
| AMI |
RHEL-7.7_HVM_GA-20190723-x86_64-1-Hourly2-GP2 |
| OS Vendor |
Red Hat, Inc. |
| Red Hat version |
7.7 |
| price per hour |
$0.17 |
Demonstration database environment
Here is a database environment summary:
| Description |
Value |
| Source version |
18.3.0 |
| Target version |
19.3.0 |
| Instances |
THING1 and THING2 |
| Instance type |
Restart |
Concurrency
Be aware that AutoUpgrade is going to launch an upgrade process for each database in the configuration file. The result is going to be multiple concurrent upgrade processes running and multiple concurrent active databases.If you are upgrading few databases on a box with a lot of memory, you will have no problem.
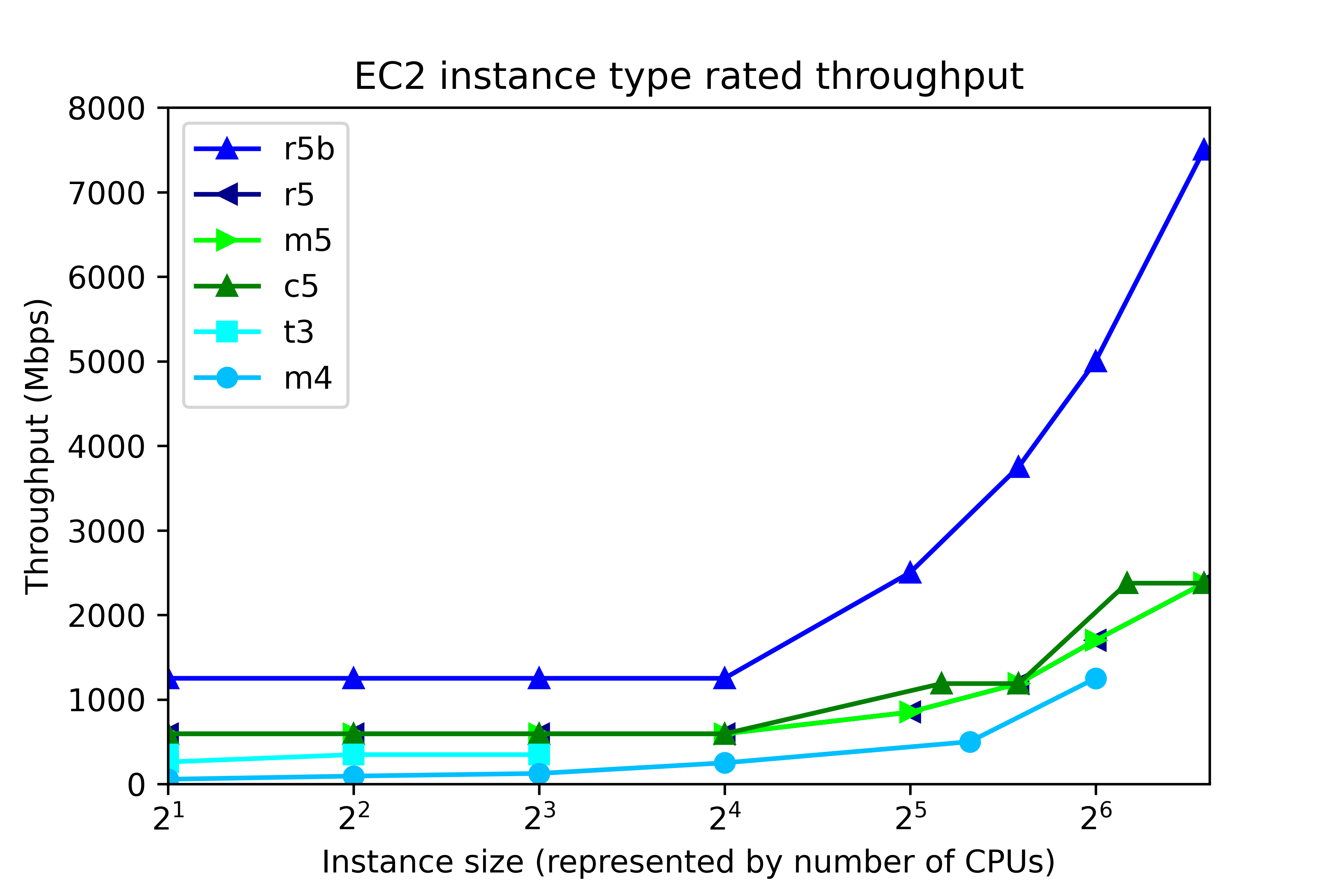
If you have multiple databases on a smaller box, you may find that the load average will reach a high level, and interactive shell response will lag. If you find that AutoUpgrade results in an unmanageable load average, there is more than one solution. For example, you could temporarily shut down some databases while you upgrade other databases. If you are in the cloud, you can get better performance by temporarily running the host image on an instance type with a higher amount of memory and CPU:
aws ec2 stop-instances --instance-ids i-00a836c352bb54daa
aws ec2 modify-instance-attribute --instance-id i-00a836c352bb54daa --instance-type '{"Value": "c5.xlarge"}'
aws ec2 start-instances --instance-ids i-00a836c352bb54daa
Finally, you may use the start_time parameter to schedule database upgrades at different future times.
Alias
Run the AutoUpgrade binary out of an Oracle home at the target version. You are going to be put into an interactive command line interface (CLI), and you are going to check on job status multiple times with the “lsj” command. For convenience, use rlwrap and create an alias.
[oracle@ip-172-31-88-93 ~]$ AH=/u01/app/oracle/product/19.3.0/dbhome_1
[oracle@ip-172-31-88-93 ~]$ alias au='rlwrap $AH/jdk/bin/java -jar $AH/rdbms/admin/autoupgrade.jar'
In this article, “au” refers to this alias.
Notice that in the alias, AH refers to an Oracle home where Java version 8 can be found. Java version 8 can be found in an Oracle 12c, 18c, or 19c Oracle home. Be sure to install the latest autoupgrade.jar into that Oracle home.
[oracle@ip-172-31-88-93 dbhome_1]$ $AH/jdk/bin/java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
If you want to run AutoUpgrade Analyze or Fixups on an Oracle 11.2.0.4 database that is on a separate host, install Java version 8 and the latest autoupgrade.jar there.
Version
AutoUpgrade distributed with Oracle Database 19.3 is version 20190207.
[oracle@ip-172-31-88-93 ~]$ au -version
build.version 20190207
build.date 2019/02/07 12:35:56
build.label RDBMS_PT.AUTOUPGRADE_LINUX.X64_190205.1800
Version 20190207 contains a bug that leads to a failure of Deploy mode on ASM. You can get the most recent version from Oracle Customer Support: AutoUpgrade Tool (Doc ID 2485457.1). As of this writing, the most recent version is:
[oracle@ip-172-31-88-93 ~]$ au -version
build.hash 67fee5b
build.version 20190823
build.date 2019/08/23 18:08:47
Configuration file
A single configuration file will be used to upgrade all instances. You may use AutoUpgrade itself to create a sample configuration file.
[oracle@ip-172-31-88-93 ~]$ au -create_sample_file config
Created sample configuration file /home/oracle/sample_config.cfg
Rename and customize the configuration file. There is one global section and multiple database sections, as many as you want. Parameter dbname actually refers to db_unique_name.
Optional AutoUpgrade configuration parameters deliver extended functionality such as changing database initialization parameters on the fly during upgrade, custom scripts to run before or after upgrade, guaranteed restore point, fixup list modification, environment variables, pluggable database upgrades, optional utlrp run, and alternate tns_admin directory location.
[oracle@ip-172-31-88-93 ~]$ mkdir -p /u01/app/oracle/autoupgrade
[oracle@ip-172-31-88-93 ~]$ cat thing1.thing2.18c.19c.conf
#Global configurations
global.autoupg_log_dir=/u01/app/oracle/autoupgrade
upg1.dbname=THING1
upg1.start_time=now
upg1.source_home=/u01/app/oracle/product/18.3.0/dbhome_1
upg1.target_home=/u01/app/oracle/product/19.3.0/dbhome_1
upg1.sid=THING1
upg1.log_dir=/u01/app/oracle/autoupgrade
upg1.upgrade_node=ip-172-31-88-93.ec2.internal
upg1.target_version=19.3
#upg1.run_utlrp=yes
#upg1.timezone_upg=yes
upg2.dbname=THING2
upg2.start_time=now
upg2.source_home=/u01/app/oracle/product/18.3.0/dbhome_1
upg2.target_home=/u01/app/oracle/product/19.3.0/dbhome_1
upg2.sid=THING2
upg2.log_dir=/u01/app/oracle/autoupgrade
upg2.upgrade_node=ip-172-31-88-93.ec2.internal
upg2.target_version=19.3
#upg2.run_utlrp=[yes|no]
#upg2.timezone_upg=[yes|no]
Recommendation: Identify $ORACLE_BASE. Set global and all database log directories to $ORACLE_BASE/autoupgrade. In every case, AutoUpgrade will create a subdirectory. You will get a directory structure like this:
/u01/app/oracle/autoupgrade/cfgtoollogs/
/u01/app/oracle/autoupgrade/THING1/
/u01/app/oracle/autoupgrade/THING2/
Analyze mode
In AutoUpgrade Analyze mode, the database instances should be running out of the Source Oracle home with the databases open.
[oracle@ip-172-31-88-93 ~]$ au -config thing1.thing2.18c.19c.conf -mode analyze
Output:
Autoupgrade tool launched with default options
+--------------------------------+
| Starting AutoUpgrade execution |
+--------------------------------+
2 databases will be analyzed
Enter some command, type 'help' or 'exit' to quit
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+--------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+--------+
| 110| THING1|PRECHECKS|PREPARING|RUNNING|19/09/26 14:06| N/A|14:06:20|Starting|
| 111| THING2|PRECHECKS|PREPARING|RUNNING|19/09/26 14:06| N/A|14:06:24|Starting|
+----+-------+---------+---------+-------+--------------+--------+--------+--------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+---------------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+---------------+
| 110| THING1|PRECHECKS|PREPARING|RUNNING|19/09/26 14:06| N/A|14:06:41| Remaining 1/72|
| 111| THING2|PRECHECKS|PREPARING|RUNNING|19/09/26 14:06| N/A|14:06:42|Remaining 67/72|
+----+-------+---------+---------+-------+--------------+--------+--------+---------------+
Total jobs 2
upg>
Job 110 for THING1 FINISHED
Job 111 for THING2 FINISHED
Locate the report. For example:
[oracle@ip-172-31-88-93 ~]$ find /u01/app/oracle/autoupgrade -name '*.html' -mmin -5
/u01/app/oracle/autoupgrade/global/cfgtoollogs/upgrade/auto/state.html
/u01/app/oracle/autoupgrade/THING1/110/prechecks/thing1_preupgrade.html
/u01/app/oracle/autoupgrade/THING2/111/prechecks/thing2_preupgrade.html
Review the report in a browser.

The report may contain Error, Warning, Recommend, and Info findings. You must address severity Error findings before attempting upgrade.
Use of Analyze mode to identify fixups
The Analyze mode runs prechecks that result in a list of changes that AutoUpgrade will make during the Fixups stage. The planned fixups appear in a “checklist” file in three formats. For example:
THING1/101/prechecks/thing1_checklist.cfg
THING1/101/prechecks/thing1_checklist.json
THING1/101/prechecks/thing1_checklist.xml
Prechecks leading to fixups are:
[oracle@ip-172-31-88-93 autoupgrade]$ < THING1/101/prechecks/thing1_checklist.json jq -r '.containers[].checks[] | select( .fixup_available == "YES" ).checkname '
DICTIONARY_STATS
POST_DICTIONARY
POST_FIXED_OBJECTS
PRE_FIXED_OBJECTS
OLD_TIME_ZONES_EXIST
MANDATORY_UPGRADE_CHANGES
The complete json checklist file is presented for information:
{
"dbname" : "THING1",
"containers" : [ {
"containername" : "THING1",
"checks" : [ {
"checkname" : "DICTIONARY_STATS",
"stage" : "PRECHECKS",
"fixup_available" : "YES",
"runfix" : "YES",
"severity" : "RECOMMEND",
"action" : "Gather stale data dictionary statistics prior to database upgrade in off-peak time using: EXECUTE DBMS_STATS.GATHER_DICTIONARY_STATS;",
"broken rule" : "Dictionary statistics do not exist or are stale (not up-to-date).",
"rule" : "Dictionary statistics help the Oracle optimizer find efficient SQL execution plans and are essential for proper upgrade timing. Oracle recommends gathering dictionary statistics in the last 24 hours before database upgrade. For information on managing optimizer statistics, refer to the 18.0.0.0 Oracle Database Upgrade Guide."
},
{
"checkname" : "POST_DICTIONARY",
"stage" : "POSTCHECKS",
"fixup_available" : "YES",
"runfix" : "YES",
"severity" : "RECOMMEND",
"action" : "Gather dictionary statistics after the upgrade using the command: EXECUTE DBMS_STATS.GATHER_DICTIONARY_STATS;",
"broken rule" : "Oracle recommends gathering dictionary statistics after upgrade.",
"rule" : "Dictionary statistics provide essential information to the Oracle optimizer to help it find efficient SQL execution plans. After a database upgrade, statistics need to be re-gathered as there can now be tables that have significantly changed during the upgrade or new tables that do not have statistics gathered yet."
},
{
"checkname" : "POST_FIXED_OBJECTS",
"stage" : "POSTCHECKS",
"fixup_available" : "YES",
"runfix" : "YES",
"severity" : "RECOMMEND",
"action" : "Gather statistics on fixed objects after the upgrade and when there is a representative workload on the system using the command: EXECUTE DBMS_STATS.GATHER_FIXED_OBJECTS_STATS;",
"broken rule" : "This recommendation is given for all preupgrade runs.",
"rule" : "Fixed object statistics provide essential information to the Oracle optimizer to help it find efficient SQL execution plans. Those statistics are specific to the Oracle Database release that generates them, and can be stale upon database upgrade. For information on managing optimizer statistics, refer to the 18.0.0.0 Oracle Database Upgrade Guide."
},
{
"checkname" : "PRE_FIXED_OBJECTS",
"stage" : "PRECHECKS",
"fixup_available" : "YES",
"runfix" : "YES",
"severity" : "RECOMMEND",
"action" : "Gather statistics on fixed objects prior the upgrade.",
"broken rule" : "None of the fixed object tables have had stats collected.",
"rule" : "Gathering statistics on fixed objects, if none have been gathered yet, is recommended prior to upgrading. For information on managing optimizer statistics, refer to the 18.0.0.0 Oracle Database Upgrade Guide."
},
{
"checkname" : "OLD_TIME_ZONES_EXIST",
"stage" : "POSTCHECKS",
"fixup_available" : "YES",
"runfix" : "YES",
"severity" : "WARNING",
"action" : "Upgrade the database time zone file using the DBMS_DST package.",
"broken rule" : "The database is using time zone file version 31 and the target 19 release ships with time zone file version 32.",
"rule" : "Oracle recommends upgrading to the desired (latest) version of the time zone file. For more information, refer to 'Upgrading the Time Zone File and Timestamp with Time Zone Data' in the 19 Oracle Database Globalization Support Guide."
},
{
"checkname" : "MANDATORY_UPGRADE_CHANGES",
"stage" : "PRECHECKS",
"fixup_available" : "YES",
"runfix" : "YES",
"severity" : "INFO",
"action" : "Mandatory changes are applied automatically in the during_upgrade_pfile_dbname.ora file. Some of these changes maybe present in the after_upgrade_pfile_dbname.ora file. The during_upgrade_pfile_dbname.ora is used to start the database in upgrade mode. The after_upgrade_pfile_dbname.ora is used to start the database once the upgrade has completed successfully.",
"broken rule" : "",
"rule" : "Mandatory changes are required to perform the upgrade. These changes are implemented in the during_ and after_upgrade_pfile_dbname.ora files."
},
{
"checkname" : "RMAN_RECOVERY_VERSION",
"stage" : "PRECHECKS",
"fixup_available" : "NO",
"runfix" : "N/A",
"severity" : "INFO",
"action" : "Check the Oracle Backup and Recovery User's Guide for information on how to manage an RMAN recovery catalog schema.",
"broken rule" : "If you are using a version of the recovery catalog schema that is older than that required by the RMAN client version, then you must upgrade the catalog schema.",
"rule" : "It is good practice to have the catalog schema the same or higher version than the RMAN client version you are using."
},
{
"checkname" : "TABLESPACES_INFO",
"stage" : "PRECHECKS",
"fixup_available" : "NO",
"runfix" : "N/A",
"severity" : "INFO",
"action" : "To help you keep track of your tablespace allocations, the following AUTOEXTEND tablespaces are expected to successfully EXTEND during the upgrade process.",
"broken rule" : "",
"rule" : "Minimum tablespace sizes for upgrade are estimates."
},
{
"checkname" : "DIR_SYMLINKS",
"stage" : "POSTCHECKS",
"fixup_available" : "NO",
"runfix" : "N/A",
"severity" : "WARNING",
"action" : "To identify directory objects with symbolic links in the path name, run $ORACLE_HOME/rdbms/admin/utldirsymlink.sql AS SYSDBA after upgrade. Recreate any directory objects listed, using path names that contain no symbolic links.",
"broken rule" : "Some directory object path names may currently contain symbolic links.",
"rule" : "Starting in Release 18c, symbolic links are not allowed in directory object path names used with BFILE data types, the UTL_FILE package, or external tables."
}]
}]
}
Fixup mode
Prior to upgrading, you may run the fixups that are recommended, possible, and available. You can see what fixups will run by running Analyze mode and reviewing the checklist file. In AutoUpgrade Fixup mode, the database instances should be running out of the Source Oracle home with the databases open.
[oracle@ip-172-31-88-93 ~]$ au -config thing1.thing2.18c.19c.conf -mode fixups
The console session:
[oracle@ip-172-31-88-93 ~]$ au -config thing1.thing2.18c.19c.conf -mode fixups
AutoUpgrade tool launched with default options
+--------------------------------+
| Starting AutoUpgrade execution |
+--------------------------------+
2 databases will be processed
Type 'help' to list console commands
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+---------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+---------------+
| 102| THING2|PRECHECKS|PREPARING|RUNNING|19/09/29 01:04| N/A|01:04:59|Loading DB info|
| 103| THING1|PRECHECKS|PREPARING|RUNNING|19/09/29 01:05| N/A|01:05:03|Loading DB info|
+----+-------+---------+---------+-------+--------------+--------+--------+---------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
| 102| THING2|PREFIXUPS|EXECUTING|RUNNING|19/09/29 01:04| N/A|01:06:28|Remaining 3/4|
| 103| THING1|PREFIXUPS|EXECUTING|RUNNING|19/09/29 01:05| N/A|01:05:21|Remaining 4/4|
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
| 102| THING2|PREFIXUPS|EXECUTING|RUNNING|19/09/29 01:04| N/A|01:06:28|Remaining 3/4|
| 103| THING1|PREFIXUPS|EXECUTING|RUNNING|19/09/29 01:05| N/A|01:06:36|Remaining 3/4|
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
Total jobs 2
upg>
upg> Job 102 completed
Job 103 completed
------------------- Final Summary --------------------
Number of databases [ 2 ]
Jobs finished successfully [2]
Jobs failed [0]
Jobs pending [0]
------------- JOBS FINISHED SUCCESSFULLY -------------
Job 102 FOR THING2
Job 103 FOR THING1
Space requirements
You must have sufficient space for archived redo logs. In this example, I upgraded two databases (6.7 GB), and consumed 9.1 GB in RECO. Diskgroup RECO01 was 40 GB and each of two databases had db_recovery_file_dest_size=20g.
Upgrade vs Deploy mode
Two upgrade modes are available, Upgrade and Deploy.
Upgrade mode performs the actual upgrade. You should run the Analyze and Fixup steps first. Upgrade mode is an appropriate choice when the upgrade will be performed on a different host from the Source version. Upgrade mode requires that you manually issue “startup upgrade” in the new Oracle home.
Deploy mode performs the Analyze, Fixup, and Upgrade steps, and additional steps, on a single host in a single execution.
Upgrade mode
Startup upgrade
If you are going to use Upgrade mode, then switch the environment to the target Oracle home. Issue “startup upgrade”.
[ec2-user@ip-172-31-88-93 ~]$ cat /tmp/initTHING1.ora
spfile='+DATA01/THING1/PARAMETERFILE/spfile.276.1019927455'
[oracle@ip-172-31-88-93 ~]$ unset ORACLE_SID
[oracle@ip-172-31-88-93 ~]$ . oraenv
ORACLE_SID = [oracle] ?
ORACLE_HOME = [/home/oracle] ? /u01/app/oracle/product/19.3.0/dbhome_1
The Oracle base remains unchanged with value /u01/app/oracle
[oracle@ip-172-31-88-93 ~]$ export ORACLE_SID=THING1
[oracle@ip-172-31-88-93 ~]$ sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Wed Sep 25 19:03:59 2019
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup upgrade pfile='/tmp/initTHING1.ora'
ORACLE instance started.
Total System Global Area 1577054672 bytes
Fixed Size 8896976 bytes
Variable Size 385875968 bytes
Database Buffers 1174405120 bytes
Redo Buffers 7876608 bytes
Database mounted.
Database opened.
SQL> Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
[oracle@ip-172-31-88-93 ~]$ export ORACLE_SID=THING2
[ec2-user@ip-172-31-88-93 ~]$ cat /tmp/initTHING2.ora
spfile='+DATA01/THING2/PARAMETERFILE/spfile.257.1019928401'
[oracle@ip-172-31-88-93 ~]$ sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Wed Sep 25 19:06:08 2019
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup upgrade pfile='/tmp/initTHING2.ora'
ORACLE instance started.
Total System Global Area 1577054672 bytes
Fixed Size 8896976 bytes
Variable Size 385875968 bytes
Database Buffers 1174405120 bytes
Redo Buffers 7876608 bytes
Database mounted.
Database opened.
SQL> Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
Run Upgrade
Start AutoUpgrade. After the upgrade has been launched in the background, you will be dropped int CLI mode. Run “lsj” from time to time to check on status.
[oracle@ip-172-31-88-93 ~]$ au -config thing1.thing2.18c.19c.conf -mode upgrade
Autoupgrade tool launched with default options
+--------------------------------+
| Starting AutoUpgrade execution |
+--------------------------------+
2 databases will be processed
Enter some command, type 'help' or 'exit' to quit
upg> tasks
+--+---------------------+-------------+
|ID| Name| Status|
+--+---------------------+-------------+
| 1| main| WAITING|
|33| jobs_mon| WAITING|
|34| mgr_help|TIMED_WAITING|
|35| watchdog|TIMED_WAITING|
|36| console| RUNNABLE|
|37| queue_reader| WAITING|
|38| cmd-0| WAITING|
|39| job_manager-0| WAITING|
|40| job_manager-1| WAITING|
|42| bqueue-108| WAITING|
|50| monitor_thing1|TIMED_WAITING|
|51| catctl_thing1| WAITING|
|52| abort_monitor_thing1|TIMED_WAITING|
|54| async_read| RUNNABLE|
|55| bqueue-109| WAITING|
|58| async_read| RUNNABLE|
+--+---------------------+-------------+
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+-------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED|MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+-------+
| 108| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:09:39|Running|
| 109| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:09:42|Running|
+----+-------+---------+---------+-------+--------------+--------+--------+-------+
Total jobs 2
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 108| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:12:46|13%Upgraded |
| 109| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:12:50|14%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 108| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:18:48|41%Upgraded |
| 109| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:18:52|42%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 108| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:21:49|49%Upgraded |
| 109| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:21:53|49%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 108| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:34:21| 0%Compiled |
| 109| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:33:12|94%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+----------+---------+-------+--------------+--------+--------+-------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED|MESSAGE|
+----+-------+----------+---------+-------+--------------+--------+--------+-------+
| 108| THING1|POSTFIXUPS|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:38:39| |
| 109| THING2|POSTFIXUPS|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:38:39| |
+----+-------+----------+---------+-------+--------------+--------+--------+-------+
Total jobs 2
upg> lsj
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED| MESSAGE|
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
| 108| THING1|POSTFIXUPS|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:40:52|Remaining 1/3|
| 109| THING2|POSTFIXUPS|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:40:55|Remaining 1/3|
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
Total jobs 2
upg> lsj
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
|JOB#|DB NAME| STAGE|OPERATION| STATUS| START TIME|END TIME| UPDATED| MESSAGE|
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
| 108| THING1|POSTFIXUPS|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:40:52|Remaining 1/3|
| 109| THING2|POSTFIXUPS|EXECUTING|RUNNING|19/09/25 19:09| N/A|19:40:55|Remaining 1/3|
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
Total jobs 2
upg>
Job 108 for THING1 FINISHED
Job 109 for THING2 FINISHED
The CLI exits when all jobs are done.
Execution time
You can find out the execution time by reviewing the logs.
/u01/app/oracle/autoupgrade/global/cfgtoollogs/upgrade/auto/autoupgrade_user.log
2019-09-25 19:09:22.185 INFO Loading user config file metadata
2019-09-25 19:09:28.405 INFO The target_base parameter was updated from N/A to /u01/app/oracle due to finding a more accurate value.
2019-09-25 19:09:28.418 INFO The target_version parameter was updated from 19.3 to 19.3.0.0.0 due to finding a more accurate value.
2019-09-25 19:09:29.444 INFO Finished processing dbEntry upg1
2019-09-25 19:09:35.597 INFO The target_base parameter was updated from N/A to /u01/app/oracle due to finding a more accurate value.
2019-09-25 19:09:35.602 INFO The target_version parameter was updated from 19.3 to 19.3.0.0.0 due to finding a more accurate value.
2019-09-25 19:09:36.627 INFO Finished processing dbEntry upg2
2019-09-25 19:09:36.634 INFO
build.version:20190207
build.date:2019/02/07 12:35:56
build.label:RDBMS_PT.AUTOUPGRADE_LINUX.X64_190205.1800
2019-09-25 19:09:36.635 INFO Current settings Initialized
2019-09-25 19:09:36.658 INFO Starting
2019-09-25 19:30:41.216 INFO Could not determine the flashback info
2019-09-25 19:30:43.240 INFO Could not determine the flashback info
2019-09-25 19:32:41.213 INFO Could not determine the flashback info
2019-09-25 19:32:43.237 INFO Could not determine the flashback info
2019-09-25 19:36:41.220 INFO Could not determine the flashback info
2019-09-25 19:36:43.253 INFO Could not determine the flashback info
2019-09-25 19:37:40.213 INFO Could not determine the flashback info
2019-09-25 19:37:41.237 INFO Could not determine the flashback info
2019-09-25 19:41:40.213 INFO Could not determine the flashback info
2019-09-25 19:41:41.238 INFO Could not determine the flashback info
2019-09-25 19:42:41.212 INFO Could not determine the flashback info
2019-09-25 19:42:43.235 INFO Could not determine the flashback info
2019-09-25 19:44:15.396 INFO Closing
Elapsed time was 34 minutes.
Deploy mode
Deploy mode completes all upgrade steps from soup to nuts: Analyze, Fixup, and Upgrade.
additional steps in Deploy mode
Deploy mode steps that are not covered by Analyze, Fixup, and Upgrade.
A careful review of the documentaion reveals that the Deploy mode implements a guaranteed restore point. You must exercise diligence to remove the restore point after it is no longer required, or you may optionally configure drop_grp_after_upgrade=yes.
Deploy mode contains a drain step, during which AutoUpgrade drains database sessions from the source instance.
Preupgrade refers to checks of your system, including disk space.
The Postupgrade documentation refers to moving the source configuation file and starting the upgraded instance. However, Upgrade mode also starts up your upgraded instance.
Deploy mode runs available fixups that correct Warning, Recommend, and Info precheck findings. AutoUpgrade makes these change without asking you. If you are using change management, be aware of, and document all changes, as required by your organization.
Run Deploy
Run deploy from the Source Oracle home with the databases opened normally. In other words, do not issue “startup upgrade” with Deploy mode.
[oracle@ip-172-31-88-93 ~]$ au -config thing1.thing2.18c.19c.conf -mode deploy
AutoUpgrade tool launched with default options
+--------------------------------+
| Starting AutoUpgrade execution |
+--------------------------------+
2 databases will be processed
Type 'help' to list console commands
upg> lsj
+----+-------+----------+---------+--------+--------------+--------+--------+---------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+----------+---------+--------+--------------+--------+--------+---------+
| 114| THING2|PREUPGRADE|EXECUTING| RUNNING|19/09/26 14:41| N/A|14:41:48| |
| 115| THING1| SETUP|PREPARING|FINISHED|19/09/26 14:43| N/A|14:41:47|Scheduled|
+----+-------+----------+---------+--------+--------------+--------+--------+---------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+--------+--------------+--------+--------+-------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+--------+--------------+--------+--------+-------------+
| 114| THING2|PREFIXUPS|EXECUTING| RUNNING|19/09/26 14:41| N/A|14:42:25|Remaining 4/4|
| 115| THING1| SETUP|PREPARING|FINISHED|19/09/26 14:43| N/A|14:41:47| Scheduled|
+----+-------+---------+---------+--------+--------------+--------+--------+-------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
| 114| THING2|PREFIXUPS|EXECUTING|RUNNING|19/09/26 14:41| N/A|14:42:25|Remaining 4/4|
| 115| THING1|PREFIXUPS|EXECUTING|RUNNING|19/09/26 14:43| N/A|14:43:51|Remaining 4/4|
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
| 114| THING2|PREFIXUPS|EXECUTING|RUNNING|19/09/26 14:41| N/A|14:45:58|Remaining 3/4|
| 115| THING1|PREFIXUPS|EXECUTING|RUNNING|19/09/26 14:43| N/A|14:47:27|Remaining 3/4|
+----+-------+---------+---------+-------+--------------+--------+--------+-------------+
Total jobs 2
upg> tasks
+---+------------------+-------------+
| ID| NAME| Job#|
+---+------------------+-------------+
| 1| main| WAITING|
| 40| jobs_mon| WAITING|
| 41| console| RUNNABLE|
| 42| queue_reader| WAITING|
| 43| cmd-0| WAITING|
| 54| job_manager-0| WAITING|
| 55| job_manager-1| WAITING|
| 58| event_loop|TIMED_WAITING|
| 59| bqueue-114| WAITING|
|200| exec_loop| WAITING|
|201| bqueue-115| WAITING|
|337| fixups-115| WAITING|
|338| rep_checks-115|TIMED_WAITING|
|340| thing1-puifx-0| WAITING|
|341| thing1-puifx-1| WAITING|
|353| quickSQL| RUNNABLE|
|388|THING2-steady-ts-0| RUNNABLE|
|400| quickSQL| TERMINATED|
+---+------------------+-------------+
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+-----------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+-----------+
| 114| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:41| N/A|14:51:53|0%Upgraded |
| 115| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:43| N/A|14:52:30|0%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+-----------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 114| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:41| N/A|14:57:58|21%Upgraded |
| 115| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:43| N/A|14:58:35|18%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 114| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:41| N/A|15:01:01|21%Upgraded |
| 115| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:43| N/A|15:01:37|21%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 114| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:41| N/A|15:07:06|37%Upgraded |
| 115| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:43| N/A|15:07:42|37%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 114| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:41| N/A|15:13:10|49%Upgraded |
| 115| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:43| N/A|15:13:46|49%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 114| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:41| N/A|15:22:17|75%Upgraded |
| 115| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:43| N/A|15:22:53|75%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> tasks
+---+---------------------+-------------+
| ID| NAME| Job#|
+---+---------------------+-------------+
| 1| main| WAITING|
| 40| jobs_mon| WAITING|
| 41| console| RUNNABLE|
| 42| queue_reader| WAITING|
| 43| cmd-0| WAITING|
| 54| job_manager-0| WAITING|
| 55| job_manager-1| WAITING|
| 58| event_loop| WAITING|
| 59| bqueue-114| WAITING|
|200| exec_loop|TIMED_WAITING|
|201| bqueue-115| WAITING|
|634| monitor_thing2|TIMED_WAITING|
|635| catctl_THING2| WAITING|
|636| abort_monitor_THING2|TIMED_WAITING|
|637| async_read| RUNNABLE|
|649| monitor_thing1|TIMED_WAITING|
|650| catctl_THING1| WAITING|
|651| abort_monitor_THING1|TIMED_WAITING|
|652| async_read| RUNNABLE|
|772| quickSQL| RUNNABLE|
+---+---------------------+-------------+
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 114| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:41| N/A|15:28:21|91%Upgraded |
| 115| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:43| N/A|15:28:58|91%Upgraded |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
| 114| THING2|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:41| N/A|15:38:14|92%Compiled |
| 115| THING1|DBUPGRADE|EXECUTING|RUNNING|19/09/26 14:43| N/A|15:38:34|79%Compiled |
+----+-------+---------+---------+-------+--------------+--------+--------+------------+
Total jobs 2
upg> lsj
+----+-------+---------+---------+--------+--------------+--------+--------+-------------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+---------+---------+--------+--------------+--------+--------+-------------------+
| 114| THING2|DBUPGRADE|EXECUTING|FINISHED|19/09/26 14:41| N/A|15:46:19|Restarting Database|
| 115| THING1|DBUPGRADE|EXECUTING| RUNNING|19/09/26 14:43| N/A|15:46:40| 98%Compiled |
+----+-------+---------+---------+--------+--------------+--------+--------+-------------------+
Total jobs 2
upg> lsj
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME|END_TIME| UPDATED| MESSAGE|
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
| 114| THING2|POSTFIXUPS|EXECUTING|RUNNING|19/09/26 14:41| N/A|15:51:05|Remaining 1/3|
| 115| THING1|POSTFIXUPS|EXECUTING|RUNNING|19/09/26 14:43| N/A|15:51:29|Remaining 1/3|
+----+-------+----------+---------+-------+--------------+--------+--------+-------------+
Total jobs 2
upg> Job 114 completed
lsj
+----+-------+-----------+---------+--------+--------------+--------------+--------+-----------------+
|Job#|DB_NAME| STAGE|OPERATION| STATUS| START_TIME| END_TIME| UPDATED| MESSAGE|
+----+-------+-----------+---------+--------+--------------+--------------+--------+-----------------+
| 114| THING2|POSTUPGRADE| STOPPED|FINISHED|19/09/26 14:41|19/09/26 15:55|15:55:23|Completed job 114|
| 115| THING1|POSTUPGRADE|EXECUTING| RUNNING|19/09/26 14:43| N/A|15:54:57| Restarting|
+----+-------+-----------+---------+--------+--------------+--------------+--------+-----------------+
Total jobs 2
upg> Job 115 completed
------------------- Final Summary --------------------
Number of databases [ 2 ]
Jobs finished successfully [2]
Jobs failed [0]
Jobs pending [0]
------------- JOBS FINISHED SUCCESSFULLY -------------
Job 114 FOR THING2
Job 115 FOR THING1
---- Drop GRP at your convenience once you consider it is no longer needed ----
Drop GRP from THING2: drop restore point AUTOUPGRADE_221145114461854_THING2
Drop GRP from THING1: drop restore point AUTOUPGRADE_221145114461854_THING1
[oracle@ip-172-31-88-93 ~]$
The final state is all databases upgraded and open.
In Deploy mode, we have a new issue. There is now a guaranteed restore point. Unless you drop the restore point, you will eventually get a stuck archiver.
SQL> select guarantee_flashback_database gua, name from v$restore_point;
GUA NAME
--- ----------------------------------------
YES AUTOUPGRADE_221145114461854_THING1
Loose ends
There are items that you must tidy up manually, even if you use AutoUpgrade in Deploy mode:
- CRS still points to the old Oracle home
- /etc/oratab still points to the old Oracle home
- in deploy mode, a guaranteed restore point exists.
Run “srvctl upgrade”.
[oracle@ip-172-31-88-93 ~]$ srvctl upgrade database -database THING1 -oraclehome /u01/app/oracle/product/19.3.0/dbhome_1
[oracle@ip-172-31-88-93 ~]$ srvctl upgrade database -database THING2 -oraclehome /u01/app/oracle/product/19.3.0/dbhome_1
You can edit oratab or run “srvctl start database”
[oracle@ip-172-31-88-93 ~]$ srvctl start database -database THING1
[oracle@ip-172-31-88-93 ~]$ srvctl start database -database THING1
[oracle@ip-172-31-88-93 ~]$ grep THING /etc/oratab
THING1:/u01/app/oracle/product/19.3.0/dbhome_1:N # line added by Agent
THING2:/u01/app/oracle/product/19.3.0/dbhome_1:N # line added by Agent
Drop the restore points
SQL> drop restore point AUTOUPGRADE_221145114461854_THING1;
Restore point dropped.
and
SQL> drop restore point AUTOUPGRADE_221145114461854_THING2;
Restore point dropped.
Bug in distribution version
The AutoUpgrade that is distributed with Oracle 19.3 does not work well with ASM. Analyze will produce a false error and Deploy mode will fail.

If you are using ASM, please download the most recent autoupgrade.jar version or use Upgrade mode only. If you use Upgrade mode, you must issue “startup upgrade” from the new Oracle home.
Conclusion
AutoUpgrade is an easy-to-use utility that upgrades multiple Oracle databases in the background. Be aware of these points:
- Do not use the distribution autoupgrade.jar. Download the latest version.
- On small hosts with multiple instances, manage CPU and memory.
- Check that your database is in archivelog mode.
- Allocate sufficient space for archive logs.
- Use an alias to simplify the command line.
- Use rlwrap for a more efficient CLI experience.
- Use Analyze mode to identify errors, warnings, and fixups.
- Use Fixup mode to apply fixups ahead of time.
- Use Upgrade mode if you wish to handle analyze, fixup, and upgrade as separate steps.
- Use Upgrade mode if you wish to migrate to a new host.
- Handle all steps automatically by using Deploy mode.
- Be aware of fixups that will be made in Deploy mode.
- Monitor progress at the CLI prompt with “lsj”
- Tie up loose ends:
- srvctl upgrade
- edit oratab
- drop restore point